ドキュメントとのチャット
情報処理の次のステップ
公開データセットと一般的な知識に依存する代わりに、「ドキュメントとのチャット」は、信頼できる内部ソースに基づいてコンテキスト特有の回答と分析を生成します。文書をアップロードし、これらの文書をチャットの質問回答の基礎として使用してください。
データ制限の解消
言語モデルに質問する場合、モデルがトレーニングされたデータセットに依存します。通常はインターネットから取得した情報です。公開されていないソースはこのデータセットには含まれていない可能性があります。チャットの情報源としてあなたの文書を使用することで、モデルがあなたの質問に必要な情報を持っていることを確実にできます。
あなたの文書を使う利点
自分の文書について、文書の主要点を挙げる、文書を要約するなどの質問をすることができます。また、独自のデータセットを用いて、言語モデルに特定の分析を実行させることも可能です。
文書ベースのチャットの欠点
文書をアップロードして処理するには追加の手順が必要です。特定情報の文脈なしでも十分に回答を得られる場合、これらの手順は不要です。また、文書から必要な情報を取得してモデルへリクエストを送る前に、処理に時間がかかることがあります。
ドキュメントでのチャットの裏側
アップロードした文書のテキストは文書から抽出され、一定の長さ(1024文字)で分割されます。分割には重複(128文字)も設定します。各テキストの断片はベクトルとしてベクトルデータベースに保存されます。質問ごとにこのデータから、質問と類似度に基づいて選択が行われます。
文書断片の選択プロセス
断片はすでにベクトル化されています。ベクトルには複数の次元があり、他のテキストとの“類似度”を示します。RGBカラー値を例に挙げると、類似したRGB値は類似した色ですが、少し異なることがあります。ベクトルデータベースは、質問に基づいてテキスト断片を整�列・フィルタリングして取得することを可能にします。質問と一致する最大100の断片を選択して、質問とともに送信します。
文書ベースのチャットに適したモデル
文書とチャットできるように、広いコンテキスト窓を持つモデルを選定しました。最大で100断片、各断片1024文字を送ることを想定しています。これらは合計で100,000文字以上になります。中央のモデルカタログから高品質モデルを優先的に使用してください。
適切なモデルとは、十分なコンテキスト領域と優れた文書分析能力を備えたモデルのことです。OpenAI、Claude、Google、欧州AIの高品質モデルなどです。
1つまたは複数の文書を選択
質問バーの右側にあるクリップのアイコンをクリックしてファイルモードを有効にできます。チャットに使用するファイルは最大10件まで選択できます。
文書とチャットを開始するとき、文書チャットに適した言語モデルかどうかを検証します。適切でない場合は、現在のカタログから自動的に適切なモデルが選択されます。
この文書に対して、ファイルモードを有効にしている限り、チャットを継続します。
ファイルごとに処理
文書とのチャットに加え、AI-Public では各文書に個別のプロンプトを適用して個別の回答を受け取る機能も提供します。この機能は「ファイルごとに処理」と呼ばれます。
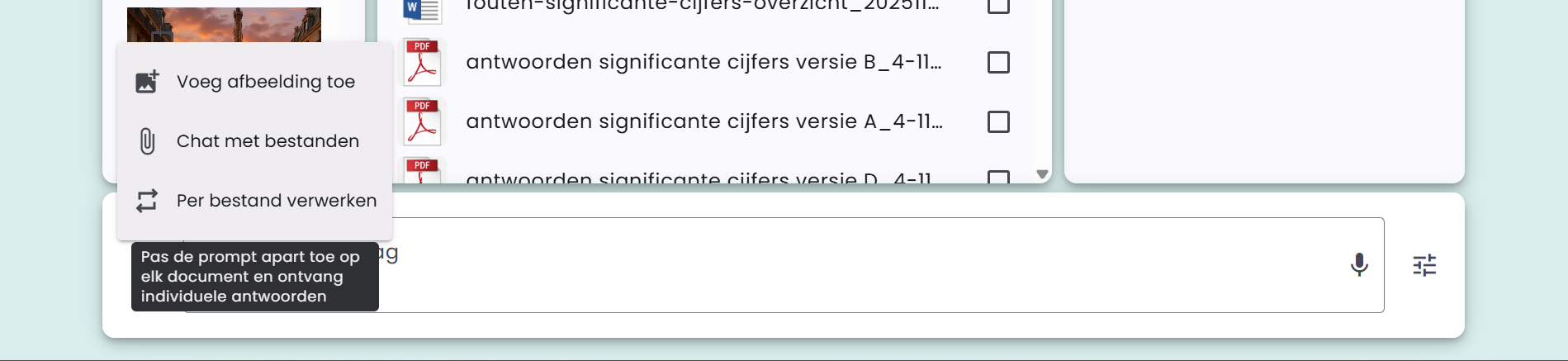
この機能は「ファイル付きチャット」と併用して使用できます。
典型的なシナリオ
「ファイルごとに処理」機能の実用例:
- 参照文書をアップロードし、ファイル付きチャットを有効にします
- 分析対象の複数の文書をアップロードし、ファイルごとに処理を有効にします
- すべてのファイルに対して適用されるプロンプトを作成します
この方法で、参照文書に基づいてすべての文書を自動的に分析させるなどの運用が可能です。
「ファイルごとに処理」機能には最大30ファイルの制限があります。
対応するファイルタイプ
AI-Public は文書とのチャットに向けて、さまざまなファイルタイプをサポートします。
- PDF (.pdf)
- Word (.docx)
- CSV (.csv)
- JSON (.json)
- テキスト (.txt)
- 音声・動画ファイル(拡張子: mp3, mp4, mpeg, mpga, m4a, wav, webm)
音声また��は動画ファイルとのチャット
AI-School は音声・動画ファイルをまず設定済みの文字起こしプロバイダーでテキスト化します。会話では、結果に時間ブロックや話者ラベルが含まれることがあります。その後、適切なテキストモデルで句読点、スペル、話者ラベル、専門用語を修正できます。長いファイルはプロバイダーやモデルの制限により短いファイルと異なる処理になる場合があります。