Belgelerle Sohbet
İşlem adımında bir sonraki adım
Kamu veri setlerine ve genel bilgiye güvenmek yerine, “Belgelerle Sohbet” güvenilir dahili kaynaklarınız temelinde bağlama özgü cevaplar ve analizler üretir. Belgelerinizi yükleyin ve bu belgeleri sohbet için yanıtlamanın temel kaynağı olarak kullanın!
Verilerin kısıtlamalarını çözme
Bir dil modeline soru yönelttiğinizde, modelin eğitim aldığı veri kümesine bağlısınız. Bu genellikle internetten elde edilen bilgilerdir. Özel olmayan kaynaklar muhtemelen bu veri kümesinde değildir. Belgelerinizi sohbetin kaynağı olarak kullanmak, modelin cevaplarınız için gereken bilgiye sahip olduğundan emin olmanızı sağlar.
Belgelerinizle ilgili Olanaklar
Belgeleriniz hakkında ana noktaları listelemek, belgenin özetini çıkarmak gibi sorular sorabilirsiniz. Ayrıca kendi veri kümenizle aracılığıyla dil modelinden özel analizler yaptırabilirsiniz.
Belge tabanlı sohbetin dezavantajları
Belgelerin yüklenmesi ve işlenmesi ek adımlardır; belirli bilgi bağlamı olmadan da iyi cevaplar alabilirsiniz. Ayrıca belgeden gerekli bilgilerin alınması ve ardından istek model gücüne gönderilmesi gerektiği için yanıtın üretilmesi daha uzun sürebilir.
Belgeyle Sohbetin Arkasındaki Kamera
Yüklediğiniz belgelerden alınan metin, belgeden çıkarılır ve parçalar halinde bölünür. Bu parçaların sabit bir karakter sayısı vardır (1024 karakter) ve parçalar arasında köpük (128 karakter) de ayarlanır. Her metin parçası bir vektör olarak bir vektör veritabanında saklanır. Her soruda, bu verilerden sorguya benzerliğe göre bir seçim yapılır.
Belge Parçacıkları Seçim Süreci
Metin parçaları zaten vektörlere dönüştürülmüştür. Vektörler, bu metnin diğer metinlerle ne kadar “benzer” olduğunu gösteren çoklu boyutlara sahiptir. RGB renk sistemini düşünün. Benzer RGB değeri olan bir renk de benzer bir renktir, fakat hafif farklıdır. Vektör veritabanı, parçaları sorguya göre sıralı ve filtrelenmiş halde getirmemizi sağlar. En fazla 100 metin parçası 1024 karakterlik olmak üzere sorguyla beraber gönderilir.
Belge tabanlı sohbet için Uygun Modeller
Belgelerle sohbeti mümkün kılmak için geniş bağlam penceresine sahip modeller seçtik. En fazla 100 parça 1024 karakterlik metin gönderebilirsiniz. Bu daha çok 100.000 karakterden fazladır. Bunun için merkezi model kataloğundan kaliteli bir dil modeli kullanmanızı öneririz.
Uygun modeller, yeterli bağlam alanı ve iyi belge analizi sunan modellerdir; OpenAI’nin, Claude’ın, Google’ın veya Avrupa AI’nin yüksek kaliteli modelleri gibi.
Bir veya birden çok belge seçin
Soru çubuğunun sağındaki ataş simgesine tıklayarak dosya modu açabilirsiniz. 10 adete kadar belgeyle sohbet etmek için bu modu kullanabilirsiniz.
Belgelerle sohbet ederken, dil modelinin belgeyle sohbet için uygun olup olmadığı kontrol edilir. Uygun değilse, mevcut kataloğa uygun bir model otomatik olarak seçilir.
Bu belgelerle, dosya modu açık kaldığı sürece sohbet edin.
Belge Başına İşleme
Belgelerle sohbetin yanı sıra, AI-Public ayrıca her belgeye ayrı bir istem uygulama ve bireysel cevaplar alma imkanı da sunar. Bu işleme “Belge Başına İşleme” adını taşır.
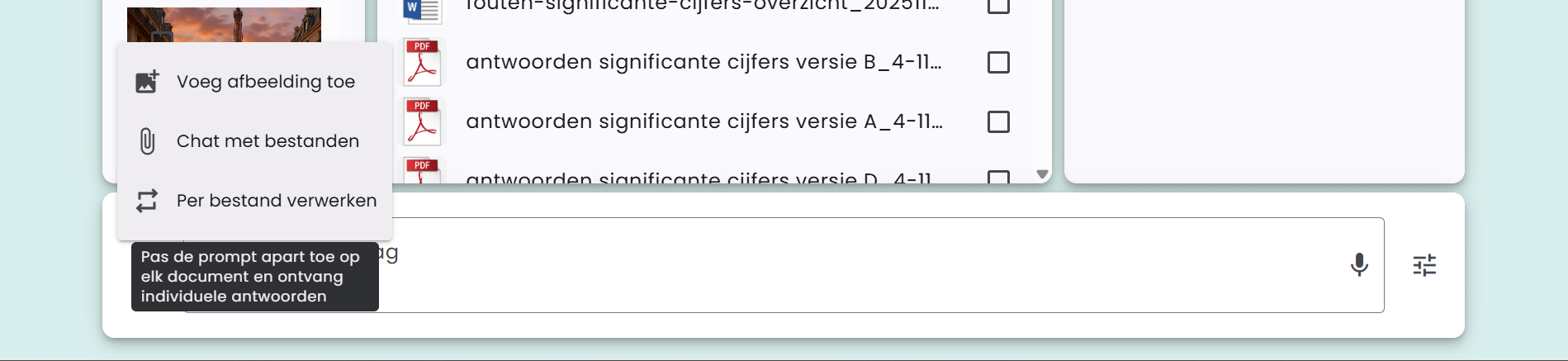
Bu işlev, “Dosyalarla Sohbet” ile birlikte kullanılabilir.
Olası senaryo
“Belge Başına İşleme” kullanımının pratik bir örneği:
- Referans belgenizi yükleyin ve “Dosyalarla Sohbet” bölümüne açın
- Analiz edilmesi gereken birden çok belgeyi yükleyin ve “Belge Başına İşleme”ye açın
- Tüm dosyalara uygulanacak bir istem ifade edin; bu, dosyaların birbirinden bağımsız olarak uygulanır
Bu şekilde, örneğin tüm belgeleri referans belgeye göre otomatik olarak analiz ettirebilirsiniz.
“Belge Başına İşleme” için bir dosya sınırı 30’dur.
Desteklenen Dosya Türleri
AI-Public, belgelerle sohbet için aşağıdaki dosya türlerini destekler:
- .pdf uzantılı PDF belgeleri
- .docx uzantılı Word belgeleri
- .csv uzantılı CSV dosyaları
- .json uzantılı JSON dosyaları
- .txt uzantılı metin dosyaları
- 'mp3', 'mp4', 'mpeg', 'mpga', 'm4a', 'wav' veya 'webm' uzantılı ses ve video dosyaları
Ses veya video dosyalarıyla sohbet etme
AI-School, ses ve video dosyalarını önce ayarlanan transkripsiyon sağlayıcısıyla metne dönüştürür. Konuşmalarda sonuç zaman blokları ve konuşmacı etiketleri içerebilir. Daha sonra uygun bir metin modeli noktalama, yazım, konuşmacı etiketleri ve vakterimleri düzeltebilir. Uzun dosyalar sağlayıcı ve model limitleri nedeniyle kısa dosyalardan farklı işlenebilir.